924
Lectures Watched
Since January 1, 2014
Since January 1, 2014
- A History of the World since 1300 (68)
- History of Rock, 1970-Present (50)
- A Brief History of Humankind (48)
- Chinese Thought: Ancient Wisdom Meets Modern Science (35)
- The Modern World: Global History since 1760 (35)
- The Bible's Prehistory, Purpose, and Political Future (28)
- Introduction aux éthiques philosophiques (27)
- Jesus in Scripture and Tradition (25)
- Roman Architecture (25)
- Sexing the Canvas: Art and Gender (23)
- Descubriendo la pintura europea de 1400 a 1800 (22)
- Introduction aux droits de l'homme (19)
- Buddhism and Modern Psychology (18)
- Calvin: Histoire et réception d'une Réforme (17)
- The Ancient Greeks (16)
- À la découverte du théâtre classique français (15)
- The French Revolution (15)
- Letters of the Apostle Paul (14)
- Key Constitutional Concepts and Supreme Court Cases (14)
- Christianisme et philosophie dans l'Antiquité (14)
- Egiptología (12)
- Western Music History through Performance (10)
- The Rise of Superheroes and Their Impact On Pop Culture (9)
- The Great War and Modern Philosophy (9)
- Alexander the Great (9)
- Greek and Roman Mythology (9)
- Human Evolution: Past and Future (9)
- Phenomenology and the Conscious Mind (9)
- Masterpieces of World Literature (8)
- Villes africaines: la planification urbaine (8)
- Greeks at War: Homer at Troy (7)
- Pensamiento Científico (7)
- MongoDB for Node.js Developers (7)
- Fundamentos de la escritura en español (7)
- Introduction to Psychology (7)
- Programming Mobile Applications for Android (7)
- The Rooseveltian Century (6)
- Karl der Große - Pater Europae (6)
- Fake News, Facts, and Alternative Facts (6)
- Reason and Persuasion Through Plato's Dialogues (6)
- The Emergence of the Modern Middle East (6)
- A Beginner's Guide to Irrational Behavior (6)
- Lingua e cultura italiana: avanzata (6)
- L'avenir de la décision : connaître et agir en complexité (5)
- Understanding Einstein: The Special Theory of Relativity (5)
- Dinosaur Paleobiology (5)
- Exploring Beethoven's Piano Sonatas (5)
- War for the Greater Middle East (4)
- Emergence of Life (4)
- Introduction to Public Speaking (4)
- The Kennedy Half Century (4)
- Problèmes métaphysiques à l'épreuve de la politique, 1943-1968 (4)
- Designing Cities (4)
- Western Civilization: Ancient and Medieval Europe (3)
- Paleontology: Early Vertebrate Evolution (3)
- Orientierung Geschichte (3)
- Moons of Our Solar System (3)
- Introduction à la philosophie de Friedrich Nietzsche (3)
- Devenir entrepreneur du changement (3)
- La Commedia di Dante (3)
- History of Rock and Roll, Part One (3)
- Formation of the Universe, Solar System, Earth and Life (3)
- Initiation à la programmation en Java (3)
- La visione del mondo della Relatività e della Meccanica Quantistica (3)
- The Music of the Beatles (3)
- Analyzing the Universe (3)
- Découvrir l'anthropologie (3)
- Postwar Abstract Painting (3)
- The Science of Religion (2)
- La Philanthropie : Comprendre et Agir (2)
- Highlights of Modern Astronomy (2)
- Materials Science: 10 Things Every Engineer Should Know (2)
- The Changing Landscape of Ancient Rome (2)
- Lingua e letteratura in italiano (2)
- Gestion des aires protégées en Afrique (2)
- Géopolitique de l'Europe (2)
- Introduction à la programmation en C++ (2)
- Découvrir la science politique (2)
- Our Earth: Its Climate, History, and Processes (2)
- The European Discovery of China (2)
- Understanding Russians: Contexts of Intercultural Communication (2)
- Philosophy and the Sciences (2)
- Søren Kierkegaard: Subjectivity, Irony and the Crisis of Modernity (2)
- The Fall and Rise of Jerusalem (2)
- The Science of Gastronomy (2)
- Galaxies and Cosmology (2)
- Introduction to Classical Music (2)
- Art History for Artists, Animators and Gamers (2)
- L'art des structures 1 : Câbles et arcs (2)
- Russian History: from Lenin to Putin (2)
- The World of Wine (1)
- Wine Tasting: Sensory Techniques for Wine Analysis (1)
- William Wordsworth: Poetry, People and Place (1)
- The Talmud: A Methodological Introduction (1)
- Switzerland in Europe (1)
- The World of the String Quartet (1)
- Igor Stravinsky’s The Rite of Spring (1)
- El Mediterráneo del Renacimiento a la Ilustración (1)
- Science of Exercise (1)
- Социокультурные аспекты социальной робототехники (1)
- Russian History: from Lenin to Putin (1)
- The Rise of China (1)
- The Renaissance and Baroque City (1)
- Visualizing Postwar Tokyo (1)
- In the Night Sky: Orion (1)
- Oriental Beliefs: Between Reason and Traditions (1)
- The Biology of Music (1)
- Mountains 101 (1)
- Moral Foundations of Politics (1)
- Mobilité et urbanisme (1)
- Introduction to Mathematical Thinking (1)
- Making Sense of News (1)
- Magic in the Middle Ages (1)
- Introduction to Italian Opera (1)
- Intellectual Humility (1)
- The Computing Technology Inside Your Smartphone (1)
- Human Origins (1)
- Miracles of Human Language (1)
- From Goddard to Apollo: The History of Rockets (1)
- Hans Christian Andersen’s Fairy Tales (1)
- Handel’s Messiah and Baroque Oratorio (1)
- Theater and Globalization (1)
- Gestion et Politique de l'eau (1)
- Une introduction à la géographicité (1)
- Frontières en tous genres (1)
- Créer et développer une startup technologique (1)
- Découvrir le marketing (1)
- Escribir para Convencer (1)
- Anthropology of Current World Issues (1)
- Poetry in America: Whitman (1)
- Introducción a la genética y la evolución (1)
- Shakespeare: On the Page and in Performance (1)
- The Civil War and Reconstruction (1)
- Dinosaur Ecosystems (1)
- Développement durable (1)
- Vital Signs: Understanding What the Body Is Telling Us (1)
- Imagining Other Earths (1)
- Learning How to Learn (1)
- Miracles of Human Language: An Introduction to Linguistics (1)
- Web Intelligence and Big Data (1)
- Andy Warhol (1)
- Understanding the Brain: The Neurobiology of Everyday Life (1)
- Practicing Tolerance in a Religious Society (1)
- Subsistence Marketplaces (1)
- Physique générale - mécanique (1)
- Exercise Physiology: Understanding the Athlete Within (1)
- Introduction to Mathematical Philosophy (1)
- What Managers Can Learn from Great Philosophers (1)
- A la recherche du Grand Paris (1)
- The New Nordic Diet (1)
- A New History for a New China, 1700-2000 (1)
- The Magna Carta and its Legacy (1)
- The Age of Jefferson (1)
- History and Future of Higher Education (1)
- Éléments de Géomatique (1)
- 21st Century American Foreign Policy (1)
- The Law of the European Union (1)
- Design: Creation of Artifacts in Society (1)
- Introduction to Data Science (1)
- Configuring the World (1)
- From the Big Bang to Dark Energy (1)
- Animal Behaviour (1)
- Programming Mobile Services for Android Handheld Systems (1)
- The American South: Its Stories, Music, and Art (1)
- Care of Elders with Alzheimer's Disease (1)
- Contagious: How Things Catch On (1)
- Constitutional Law - The Structure of Government (1)
- Narratives of Nonviolence in the American Civil Rights Movement (1)
- Christianity: From Persecuted Faith to Global Religion (200-1650) (1)
- Age of Cathedrals (1)
- Controversies of British Imperialism (1)
- Big History: From the Big Bang until Today (1)
- Bemerkenswerte Menschen (1)
- The Art of Poetry (1)
- Superpowers of the Ancient World: the Near East (1)
- America Through Foreign Eyes (1)
- Advertising and Society (1)
Hundreds of free, self-paced university courses available:
my recommendations here
my recommendations here
Peruse my collection of 275
influential people of the past.
influential people of the past.
View My Class Notes via:
Receive My Class Notes via E-Mail:
Contact Me via E-Mail:
edward [at] tanguay.info
Notes on video lecture:
Scalability Basics
Notes taken by Edward Tanguay on July 2, 2014 (go to class or lectures)

Choose from these words to fill the blanks below:
datasets, memory, matching, touch, SQL, preprocessing, trees, computers, reusing, core, complexity, old, baked, load, footprint
•
what does scalability mean?
•
operationally
•
in the past, "scale up"
•
needs to work even if data doesn't fit in main on one machine
•
need to bring in data, work on it, then bring in more data, work on it, etc.
•
what was important was the size of the memory
•
this was "out of " processing of large datasets
•
but this began to not be enough since you couldn't bring data on and off fast enough to satisfy the
•
now, "scale out"
•
you can increase the speed that you can process the data by making use of 1000s of cheap
•
algorithmically
•
in the past
•
algorithm is scalable if when you have n data items, you must do no more than n^m operations, where m is 1 or 2 or some low number, with 4 and beyond it becomes difficult for large
•
this was tractable, became the definition of scalable
•
now:
•
n^m/k where k is the number of computers you can apply to the problem
•
soon, "streaming data"
•
"if you have n data items, you should do no more that n * log(n) operations
•
as data grows, you may only get one pass at it
•
whenever you hear "log" you should think " " so this enables you to look at each item and put it in some tree data structure
•
example: Large Synoptic Survey Telescope (30TB / night)
•
example 1: "Needle in Haystack"
•
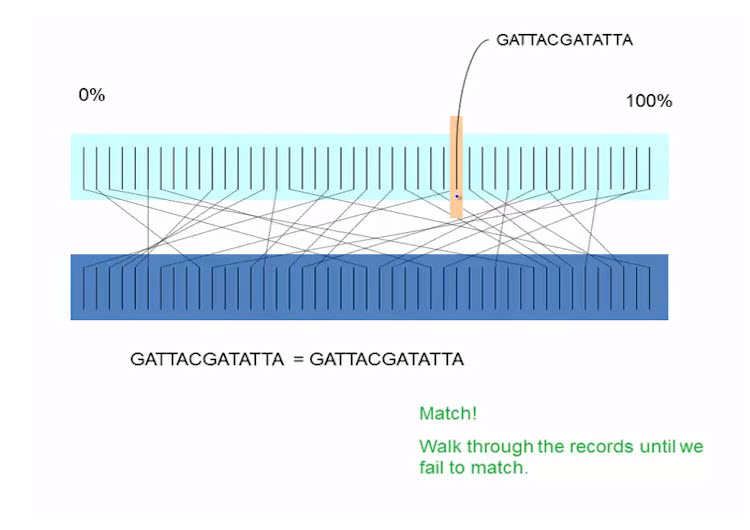
find DNA sequences that equal "GATTACGATATTA"
•
linear search
•
move through each, compare, until you get a match
•
40 records, 40 comparisons
•
n records, N comparisons
•
algorithmic is order N
•
sort the sequences
•
sort them first, then start in the middle, and move to the direction of the one you are looking for
•
after the first check, you remove the need to check half the data
•
40 records, 4 comparisons
•
but we had to sort the data ahead of time
•
algorithmic complexity is log(N) comparisons
•
this type of approach to search is into databases, i.e. "needle in haystack" problems
•
e.g. CREATE INDEX seq_idx ON sequence
•
this is -style scalability, i.e. it fits in memory
•
builds a platform for building and indexes
•
"there is a lot of work that you are getting for free just by turning your problem into an statement"
•
example 2: "Read Trimming"
•
given set of DNA sequences, trim a suffix of each and create a new dataset
•
this is a standard operation
•
linearly
•
loop through and process each
•
there is no index that is going to help us here, you have to at least every record
•
how can we do better?
•
the processing of each doesn't have to do with the processing of the other
•
therefore, break dataset into a number of groups and give groups to different processors which process simultaneously
•
complexity is N/k, where
•
N is the number of items to operate
•
k is the number of workers
Vocabulary:
| tractable, adj. of a decision problem, algorithmically solvable fast enough to be practically relevant, typically in polynomial time ⇒ "This algorithm proved to be tractable and became the definition of scalable." |